
As a long-time fan of Lain and somewhat of a hobby-archivist, I’ve come to greatly appreciate fan sites. They show the true life and breadth of a fandom, with each person’s personal spin on what the series means to them, the aesthetics they associate with it, and the creations they’ve made to honor it.
Any time you look at a fan site, you’re looking at tens to hundreds of hours of time dedicated to a specific topic. Graphics that were custom-made for the site, links that were hand-curated over many months/years, a gallery of CGs that was collected from all across the internet, perhaps even stories, notes on the script, or their own interpretation of the plot written up in pages and pages of text.
These sites represent immense amounts of human energy poured into a single topic. They are, without a doubt, some of the purest forms of original content: Creations made solely out of a love and passion for a shared topic. A site with no real purpose other than sharing their love even more widely, or to form a bond with other fans. A selfless endeavor, where the fan themselves comes second, and the anime, show, game, etc. comes first.
Of course, this is all my own biased opinion: You’re reading this on a fan site, so I’m tooting my own horn, waxing poetic as if I was an outsider while actively engaging in fan site creation…
Anyways, on to the real topic: fan site archaeology.
As part of this love of fan sites, I would like to preserve them. I think that keeping their memory alive helps to further spread the energy and love that was invested into the creation of these sites. For each set of eyes that graces their homepage, the creator’s dedication is rewarded in some small way, transferring some of their intense energy into the viewer.
And as such, I’d like to do what I can to keep that energy alive. In the past, I’ve enjoyed browsing old fan websites through the Internet Archive, sharing their links and contents when I find something interesting. But recently, I’ve realized an issue with this approach: accessibility!
The Internet Archive Accessibility Issue
First, a tl;dr of the issue: It’s easy to find sites on the internet archive if you know the domain. If you don’t, it’s impossible to find them!
When a site is archived on the Wayback Machine or in the Internet Archive, it is preserved – but it is not searchable. Unless you know the URL, you can not search the contents of pages archived on the Wayback Machine. I believe this is due to resource limitations and server costs: Indexing all of the information on the Wayback Machine to make it instantly searchable would be a herculean engineering effort, and come with quite a large server bill. Additionally, it opens up a whole can of worms of “liability” in the search results, SEO engineering, and all sorts of other annoying problems.
And so, we have a problem: The most popular Lain fansites have well-known URLs that have stuck around on Google, through their references in old forum posts, personal websites, blogs, etc. But, these references are slowly disappearing. Take for example the relatively popular Japanese-language Lain fansite “lain.pos.to”.
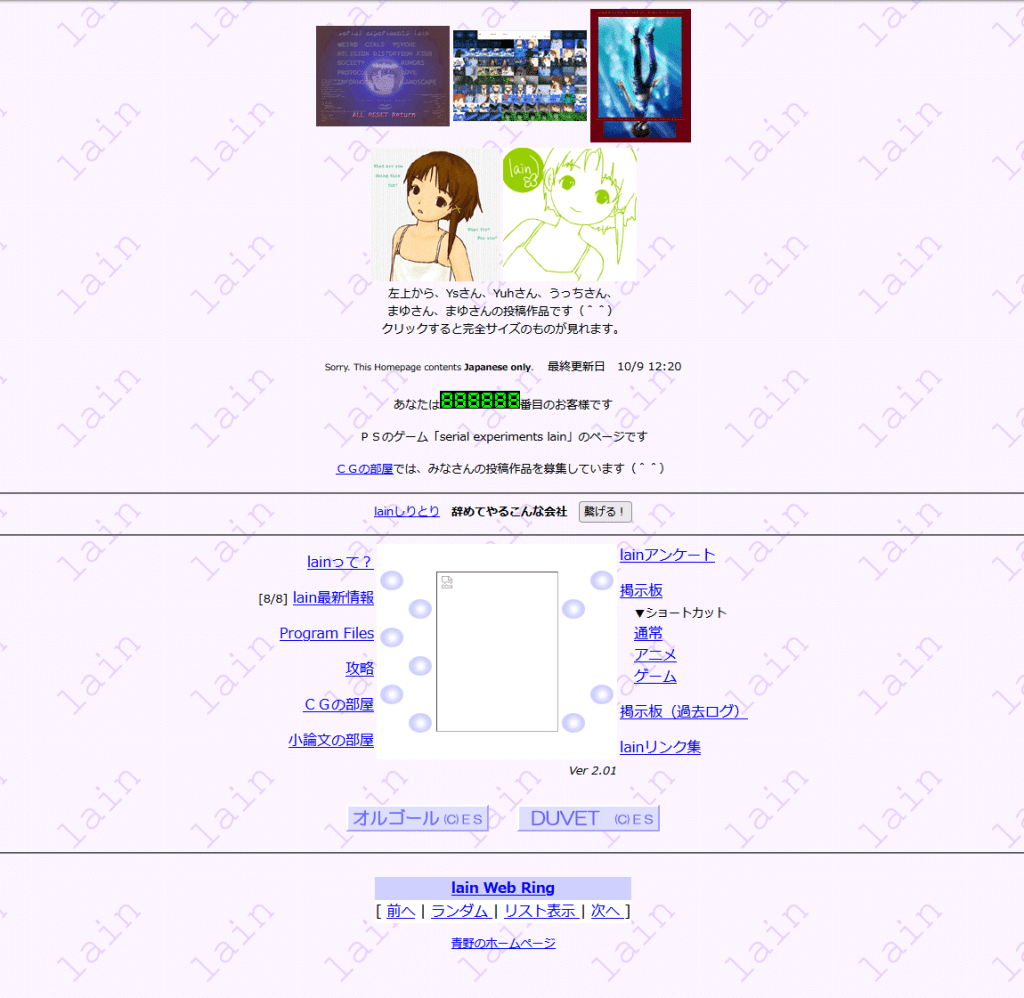
This website hosts a wealth of information on the early fandom, and is an invaluable resource for learning more about the timelines surrounding Lain’s release in Japan. It has information on when various magazines came out, when the trailers were first released, pre-order and freebie giveaways that occurred at stores in Japan, and more.
But if you search this website’s domain on DuckDuckGo:
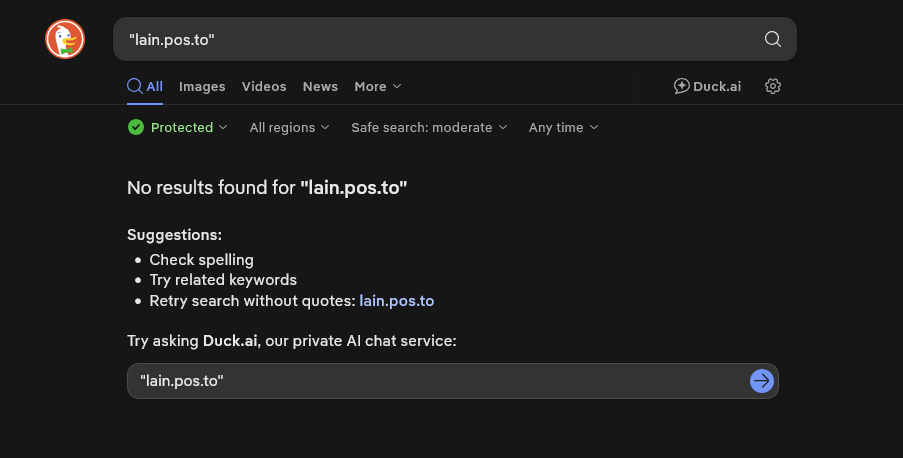
Zero results. Google fares slightly better here:
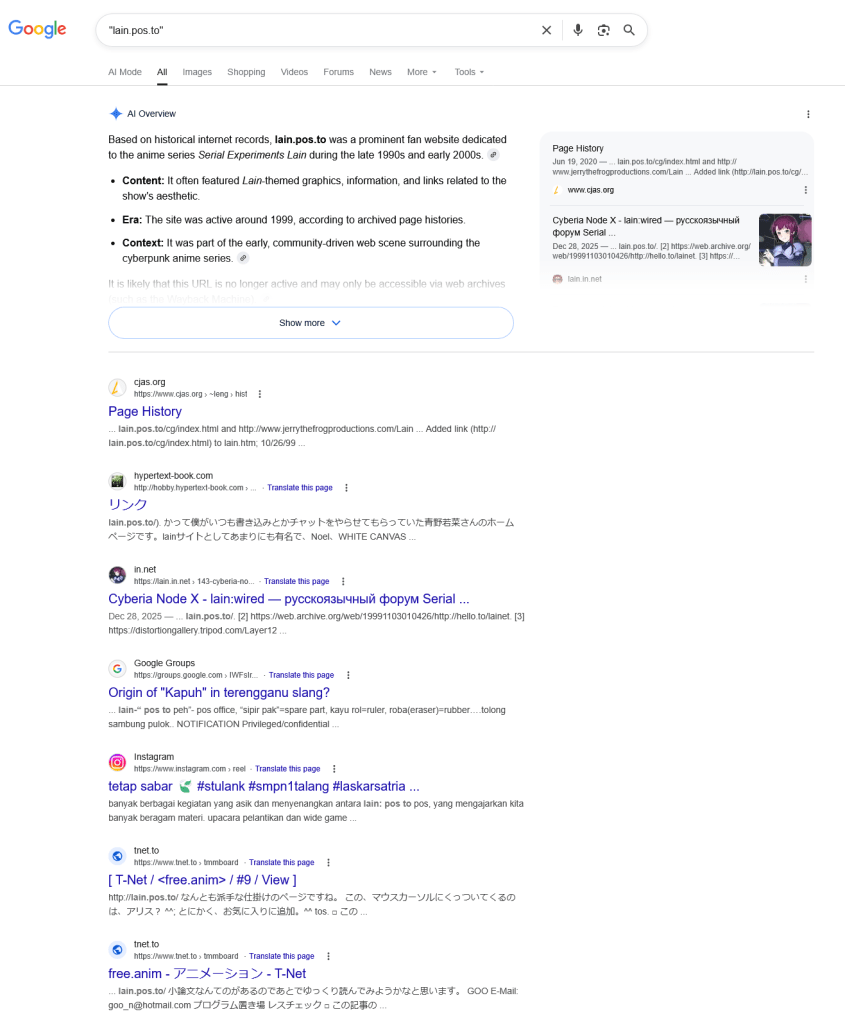
But even with Google – seven total results, and two are irrelevant. Finding this fansite using Google in 2026 would be like finding a needle in a haystack if you didn’t already know the URL.
But now, if we pivot over to the Internet Archive/Wayback Machine:
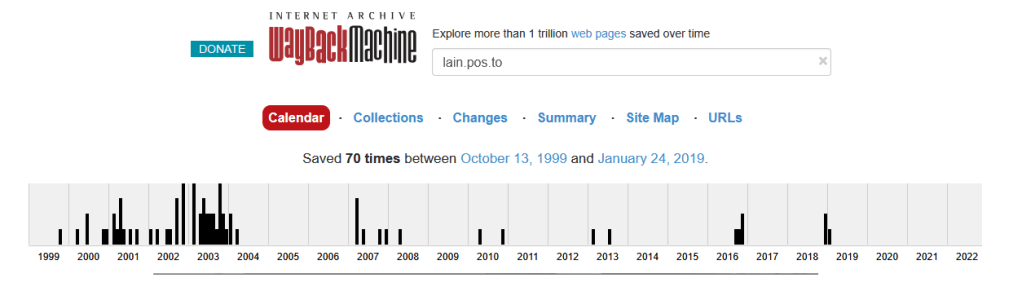
The site has been saved 70 times on the Internet Archive, dating back to 1999! This shows that it could be a great resource to learn more about the early Lain fandom… IF you know the URL to search.
And so, I think this presents an issue that’s waiting for a solution: Who is going to create a list of all of the Lain fansite URLs, past, present, and future?
Collecting Lain Fan Site URLs
To help solve this issue, I’d like to create a bulk collection of Lain fan site URLs. This will be a fully-manual process at first, but it’s something that I’d like to be able to support using automation, to help find fansites that are buried in the Internet Archive and don’t exist on the modern internet.
As a place to start, I’ve begun collecting bulk URL data from the Internet Archive. You can use their CDX API to query URLs that have been archived for a given site. As such, I’ve started to collect a list of every single URL archived from major Japanese free web hosting sites between 1996 and 2010. My plan is to then search these URLs for keywords like “serialexperimentslain”, “lain”, etc. as a way of locating Lain content and fan websites across the Internet Archive.
In the screenshot above, you can see the script making CDX queries, currently collecting all of the URLs archived for cool.ne.jp. Unfortunately, you can also see some of the limitations of the IA API: A lot of 503 and 504 errors, and even some weird HTTP 200 responses with a fully empty body. My script implements a multiplier on all of the timeouts to back off any time errors are being raised in the IA API, so as to be respectful to any API limits and not overload the service. That being said, at least according to users on Reddit, the CDX API is just unfortunately buggy/overladen – you’re expected to get 5xx errors for a majority of your requests.
Spidering for More Fansite URLs
The next step will be spidering (web crawling) out from these URLs to identify linked-but-unknown fan sites. I’ve begun the first steps of creating a spider, but it is still in it’s infancy. Currently, you feed the script an initial ‘seed’ URL and it performs the following steps:
- Query the Internet Archive for the seed URL, with an optional target date (ie: 2000-01-01) for the archive snapshot
- Create a list of all pages present on the website
- Search the contents of all pages for specific Lain keywords
- Lain, Serial Experiments Lain, etc. – need to refine this still
- Give the website a “lain relevancy score” based on the results of the keyword search
- If the site contains no Lain keywords, score is 0
- The site gets +1 score for each instance of a Lain keyword
- If the site score is above a specific threshold, it is accepted for spidering (still tuning this, threshold currently 1 lol)
- All pages on the site are searched for external URLs
- These URLs are added to the spidering queue
- If the site score is below the threshold, the URL is added to an “ignore list” and it is no longer spidered
- The script then continues on to the next site in the queue
With this format, sites are only spidered or saved if they contain a sufficient amount of Serial Experiments Lain content. This helps to not spider or collect links for irrelevant websites.
Finally, I can sort the final list of URLs by their lain relevancy score. I then browse all of the highest-scoring sites to see whether they’re actually Lain fansites, and add them to the fansite list if they are.
Internet Archive and Spidering Caveats
I know: This isn’t foolproof. A few known issue scenarios: A big retailer like Animate might have a ton of Lain content, but only because they sold all of the Lain DVDs. An artist who draws Lain art on a small “CG Blog” might not use Lain keywords on their site at all, but may have tons of Lain artwork uploaded, which the script can’t parse at all – and the site would be unfairly skipped.
Overall, I don’t have a perfect solution to these issues. I’ll do my best to keep improving the script, but I see this as ‘harm reduction’ – I think saving any Lain fansites is better than saving none, so I’ll do what I can to keep collecting bulk URLs and fine-tuning my approach.
Future Fun Projects?
If the result of this data is a bulk list of Lain-related URLs, I was thinking: there are lots of things you could do with that data!
One of the first things I’d like to do is create a bot that could automatically load the Wayback Machine’s snapshot for a given URL and screenshot it. Having screenshots of the homepage of all of these Lain fansites would be a lot more accessible to browse through visually, and could make for a fun showcase of the Lain fandom’s take on early 2000’s web design 🙂
It could also be fun to collect some statistics on Lain fansites and their hosts. What was the most popular web host among Lain fansites, were there any stand-out winners? What percentage of Lain fansites were hosted on people’s personal college pages? And by extension, what school in the early 2000’s had the most Lain fans?
There are many ways to experiments and play with bulk datasets like this, so I’m sure there will be many fun projects to come once I get a bulk fansite URL list up and going.
Conclusion
Well, that’s about it! I wanted to write about my current fansite archaeology, and I felt that I was long-overdue for a new blog post. In the past, my blog posts have mainly centered around other people’s actions in the fandom, but I thought: why not talk about my own projects too? So I’m trying out a new posting style now.
I’m hoping to continue working on these tools and build an actual list of old Lain fansite URLs. When I release it, you should see it on the homepage, and I’ll write a blog post about it!
A side note on datasets and research usage:
I’m currently saving these URLs to local JSON files – so I currently have dozens of gigabytes of URL entries, soon to be hundreds of gigs. I’m assuming this could make for an interesting research dataset, since you can perform all sorts of searches against the URLs of millions of old websites.
If you have any interest in the data, let me know – perhaps I could find a way to get it to you, or at least let you know what kind of CDX request formatting I was using.
Current total dataset size: 38.2M URLs, 10.4 GB
As for hosts, I’m currently collecting all URLs archived between 1996-01-01 and 2010-12-31 for the following Japanese hosts:
- Geocities Japan
- geocities.co.jp
- geocities.jp
- Nifty member pages
- homepage1.nifty.com
- homepage2.nifty.com
- homepage3.nifty.com
- members.nifty.com
- Major ISP personal pages
- biglobe.ne.jp
- so-net.ne.jp
- plala.or.jp
- ocn.ne.jp
- dti.ne.jp
- bekkoame.ne.jp
- rim.or.jp
- Free hosting services
- cool.ne.jp
- tok2.com
- fc2web.com
- web.fc2.com
- xrea.com
- infoseek.co.jp
- cside.com
- interq.or.jp
- angel.ne.jp
- justnet.ne.jp
- din.or.jp
- orion.ne.jp
- tripod.co.jp
- pos.to
- oekakibbs.com
- freepage.total.co.jp
- mbn.or.jp
- page.freett.com
I’m hoping to start looking for international/western fansite URLs next, but I still need to build up a bigger list of domains and free website hosts that would have been common for fansites in the early 2000s. Currently, I have:
- geocities.com
- tripod.com
- angelfire.com
- fortunecity.com
- homestead.com
- freeservers.com
- members.aol.com
- crosswinds.net
- hypermart.net
- freewebs.com
- webs.com
If you have any suggested domains to add to this list or collect URLs for, please let me know! 🙂
And, a final note on the source code of my various internet archive scripts: I don’t think I’ll be releasing it. To be 100% honest: These Internet Archive scraping scripts have been vibe coded with Claude Code. I’m not going to lie, I feel like beating the AI’s head in whenever I’m working on it, it constantly loses context and makes dumb mistakes – but I’ve eventually beaten the features that I want into the script. Because of this, it’s a horrific 3,000 LoC monstrosity of a Python script. So I could open-source it, but it feels like a crime releasing such a burning pile of rubbish into the public. Is there such a thing as littering on GitHub? Because this would fit the bill. So yeah, I’m hiding my shame and crappy vibe coded source code admissions down here at the bottom of the blog post T_T

Leave a comment